



【导(dǎo)语(yǔ)】传(chuán)统(tǒng)任(rèn)务(wu)与(yǔ)运(yùn)动(dòng)规(guī)划(huà)(TAMP)系(xì)统(tǒng)依(yī)赖(lài)静(jìng)态(tài)模(mó)型(xíng),面(miàn)对(duì)新(xīn)环(huán)境(jìng)表(biǎo)现(xiàn)欠(qiàn)佳(jiā),将(jiāng)感(gǎn)知(zhī)与(yǔ)操(cāo)作(zuò)融(róng)合(hé)是(shì)破(pò)局关键。本期NVIDIA机器人研发摘要(R²D²)聚焦于此,探讨基于感知及GPU加速的TAMP实现远程操作,介绍提升机器人操作能力的框架,解析如何将视觉与语言信息转化为具体动作,还涉及cuTAMP加速规划、机器人从故障学习等内容,助力开发者了解NVIDIA在物理AI与机器人应用领域的突破。
传统的任务与运动规划(TAMP)系统在机器人操作应用中通常依赖静态模型运行,因此在面对新环境(jìng)时(shí)往(wǎng)往(wǎng)表(biǎo)现(xiàn)不(bù)佳(jiā)。将(jiāng)感(gǎn)知(zhī)与(yǔ)操(cāo)作(zuò)相(xiāng)融(róng)合(hé),是(shì)应(yīng)对(duì)这(zhè)一(yī)挑(tiāo)战(zhàn)的(de)有(yǒu)效(xiào)途(tú)径,使(shǐ)机(jī)器(qì)人(rén)能(néng)够(gòu)在(zài)执行过程中实时更新规划,从而适应动态变化的场景。
在本期NVIDIA 机器人研发摘要 (R²D²)中,我们探讨了如何利用基于感知的 TAMP 以及 GPU 加速的 TAMP 实现远程操作。同时,我们将介绍用于提升机器人操作能力的框架,并展示如何结合视觉与语言信息,将像素转化为子目标、任务负载以及可微分的约束条件。
子目标是较小的阶段性目标,能够引导机器人逐步达成最终目标。
Affordance 根据物体或环境的属性及其所处的上下文,描述机器人可在其上执行的动作。例如,手柄可被“抓取”,按钮可被“按压”,杯子可被“倾倒”。
在机器人运动规划中,可微分约束用于确保机器人的运动满足物理限制,如关节角度范围、避障要求或末端执行器的位置精度,同时仍支持通过学习进行调整。由于这些约束具备可微性,GPU 能够在训练或实时规划过程中高效地计算并优化它们。
任务与运动规划如何将视觉与语言信息转化为机器人的具体动作
TAMP 涉(shè)及(jí)确(què)定(dìng)机(jī)器(qì)人(rén)应(yīng)执(zhí)行(xíng)的(de)任(rèn)务(wu)以(yǐ)及(jí)实(shí)现(xiàn)这(zhè)些(xiē)任(rèn)务(wu)所(suǒ)需(xū)的(de)移(yí)动(dòng)方(fāng)式(shì),需(xū)要(yào)将(jiāng)高(gāo)层(céng)任(rèn)务(wu)规(guī)划(huà)(即(jí)执(zhí)行(xíng)什(shén)么(me)任(rèn)务(wu))与底层运动规划(即如何移动以完成任务)相结合。
现代机器人能够结合视觉与语言信息(如图像和指令),将复杂任务分解为若干较小的步骤,即子目标。这些子目标有助于机器人明确下一步应执行的动作、需要交互的对象以及如何实现安全移动。
该过程利用高级模型将图像和书面指令转化为机器人可在现实世界中执行的清晰计划。远程操作需要具备结构化意图,且依赖规划人员的有效参与。接下来,我们将探讨 OWL-TAMP、VLM-TAMP 和 NOD-TAMP 如何助力解决这一问题:
OWL-TAMP:该工作流使机器人能够执行以自然语言描述的复杂、长视距操作任务,例如“将橙色物体放到桌子上”。OWL-TAMP 是一种混合式工作流,将视觉语言模型(VLM)与任务与运动规划(TAMP)相结合。其中,VLM 根据开放世界语言(OWL)指令生成约束条件,描述机器人动作空间中的操作要求。这些约束被整合进 TAMP 系统,并通过仿真反馈机(jī)制(zhì)验(yàn)证(zhèng)其(qí)物(wù)理(lǐ)可(kě)行(xíng)性(xìng)和(hé)执(zhí)行(xíng)正(zhèng)确(què)性(xìng)。
VLM-TAMP:这(zhè)是(shì)一(yī)种(zhǒng)面(miàn)向(xiàng)视(shì)觉(jué)信(xìn)息丰富环境的机器人多步骤任务规划工作流。VLM-TAMP 将视觉语言模型与传统 TAMP 框架融合,能够在现实场景中生成并优化高层行动计划。该方法利用 VLM 解析图像内容,并结合任务指令(如“做一锅鸡汤”)生成初步的高级任务规划。随后,通过仿真验证和运动规划进行迭代优化,以确保每一步操作的可行性。在涉及 30 至 50 个连续动作、并操作多(duō)达(dá) 21 个(gè)不(bù)同(tóng)物(wù)体(tǐ)的(de)长(zhǎng)视(shì)距(jù)厨(chú)房(fáng)任(rèn)务(wu)中(zhōng),该(gāi)混(hùn)合(hé)方(fāng)法(fǎ)的(de)表(biǎo)现(xiàn)优(yōu)于(yú)纯(chún) VLM 或(huò)纯(chún) TAMP 的(de)基(jī)准(zhǔn)方(fāng)案(àn)。该(gāi)工作流使机器人能够综合利用视觉与语言上下文信息,有效应对任务描述中的模糊性,从而提升在复杂操作任务中的整体性能。

图1展示了VLM-TAMP如何克服单独使用TAMP或仅依赖VLM进行任务与运动规划在解决长视距机器人操作问题时所面临的局限性。
NOD-TAMP: 传统的TAMP框架在处理长视距操作任务时通常难以实现泛化,因其依赖于显式的几何模型和对象表示。NOD-TAMP通过引入神经对象描述符(NOD)来提升对不同对象类型的泛化能力。NOD是一种基于3D激光点云学习得到的表示形式,能够编码物体的空间特征与关系属性。该方法使机器人能够与新对象有效交互,并支持规划器进行动态的操作调整。
cuTAMP 如何利用 GPU 并行化加速机器人规划
经典 TAMP 首先分析任务的动作结构(称为(wèi)计(jì)划(huà)骨(gǔ)架(jià)),再(zài)求(qiú)解(jiě)相(xiāng)应(yīng)的(de)连(lián)续(xù)变(biàn)量(liàng)。第(dì)二(èr)步通常是系统的计算瓶颈,而cuTAMP显著加速了这一过程。对于cuTAMP中给定的计划骨架,系统会采样数千个初始解(粒子),随后在 GPU 上执行可微分的批量优化,以满足多种约束条件,例如逆运动学、避障、稳定性以及目标函数成本。
如果框架不可行,算法会进行回溯;如果可行,则会生成一个计划。对于受限的打包或堆叠任务,该过程通常在几秒钟内完成,使机器人能够在几秒内找到包装、堆叠或操作多个物体的解决方案,而无需花费几分钟甚至几小时。
“矢量化满意度”是实现在现实应用场景中长期解决问题的关键。
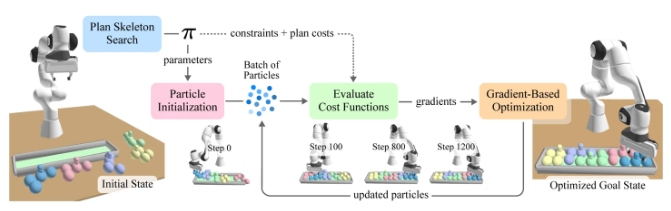
图2展示了cuTAMP如何将TAMP帧化为一种回溯式的双层搜索,以优化计划骨架。
机器人如何利用Stein变分推断从故障中学习
长距操作模型在面对训练过程中未曾遇到的新条件时,可能会出现失效。Fail2Progress是一种使机器人能够从自身失败中学习并持续改进操作能力的框架。该框架通过数据驱动的校正与基于仿真的优化,将实际发生的故障整合进技(jì)能模型中。为了增强模型的鲁棒性,Fail2Progress 利用 Stein 变分推断生成与观测到的故障相似的定向合成数据集,从而有效提升模型对异常情况的适应能力。
然后,这些生成的数据集可用于微调并重新调整技能效果模型,从而降低长视野任务中相同故障重复发生的次数。
入门指南
在这篇博客中,我们探讨了基于感知的TAMP、GPU加速的TAMP,以及用于机器人操作的基于仿真的优化框架。我们分析了传统TAMP中常见的挑战,并介绍了这些研究工作为应对这些挑战所提出的方法与思路。
本文是NVIDIA 机器人研发摘要(R²D²)系列的一部分,旨在帮助开发者深入了解(jiě)NVIDIA Research在(zài)物(wù)理 AI 与机器人应用领域的最新突破。
